

We're making WorqHat Database—a WorqHat-hosted SQL (OLAP) database with a spreadsheet interface—generally available to all customers over the next few days. With WorqDB, you can spend less time on setup and more time on building. Upgrade spreadsheet-based processes into secure and scalable apps, all in just a few minutes.
In boardrooms and team meetings around the globe, a common story unfolds. A company celebrates explosive growth—more users, more transactions, more data than ever before. Yet, the teams tasked with understanding this success are struggling. Business intelligence dashboards crawl, taking minutes to load. Critical reports that once took an hour now take half a day. Answering a simple, ad-hoc question from an executive becomes a multi-hour ordeal of data extraction and manual processing. This is the analytics bottleneck, a paradoxical state where a company's greatest asset, its data, becomes its heaviest burden.
A New Blueprint for Speed: The Foundational Philosophy of WorqDB
The limitations of existing tools necessitated a new design philosophy. WorqDB was conceived with a singular, focused mission: to provide the fastest possible answers to complex analytical queries on massive datasets. This required a deliberate departure from the "one-size-fits-all" model that forces compromises between transactional and analytical performance.
Engineering for Analytics First
The core principle behind WorqDB is specialization. While traditional databases must balance the demands of both reading and writing data to support transactional workloads, WorqDB is unapologetically optimized for read-heavy, high-throughput analytical operations. Its architecture prioritizes the speed of large-scale data scans, aggregations, and filtering over the efficiency of single-row updates or deletes that are characteristic of OLTP systems. This focus allows for architectural choices that would be untenable in a general-purpose database but are essential for achieving orders-of-magnitude performance gains in analytics.
Embracing Modern Hardware and Distributed Systems
Legacy database designs were shaped by the hardware constraints of their time: slow spinning disks, single-core processors, and limited memory. WorqDB was engineered from the ground up to exploit the capabilities of modern infrastructure. Its design assumes and leverages multi-core CPUs, the low latency of solid-state drives (SSDs), and the near-infinite scalability of cloud computing, where systems can be distributed across hundreds or thousands of commodity servers.
The Power of an Integrated Design
This modern approach recognizes that peak performance is not achieved through a single feature but through a holistic, integrated system. The core architectural pillars of WorqDB—columnar storage, vectorized query execution, and massively parallel processing—are not independent components but a synergistic trio.
The columnar data layout provides a perfectly structured input for the CPU's parallel processing capabilities (SIMD). Vectorized execution processes these columns with unparalleled efficiency on a single node. Massively parallel processing then takes this hyper-efficient single-node engine and scales it out horizontally across a cluster. This integrated design, where each component amplifies the others, creates a system where performance scales predictably and cost-effectively from a single powerful machine to a vast, distributed cluster.
Under the Hood: The Architectural Pillars of WorqDB's Performance
WorqDB's remarkable speed is not magic; it is the result of three foundational architectural decisions that work in concert to minimize I/O, maximize CPU efficiency, and enable limitless scale.
Pillar 1: Columnar Storage - Read Only What You Need
The most fundamental difference between WorqDB and traditional databases is its columnar storage format. In a conventional row-store database, all the data for a single record (e.g., a customer's ID, name, address, and signup date) is stored together contiguously on disk. In a column-store, all the values for a single column (e.g., all signup dates for all customers) are stored together.
An effective analogy is a phone book. A row-store is like a standard phone book sorted by name; to find the average age of everyone in a city, one would have to read every single entry on every page. A column-store is like having separate, dedicated lists for names, addresses, and ages. To find the average age, one simply grabs the "age" list and can completely ignore the others.
This approach yields two transformative benefits for analytics:
Drastically Reduced I/O: Analytical queries rarely need all columns in a table. By reading only the specific columns required to answer a query, WorqDB minimizes disk and network I/O, which is the most significant performance bottleneck in large-scale data processing.
Superior Data Compression: Storing similar data types together allows for the use of highly effective, specialized compression algorithms. For example, a column of repeating strings can be efficiently compressed using dictionary encoding, while a column of sequential timestamps can be compressed using delta encoding. This not only reduces the storage footprint by a significant margin but also means less data needs to be read from disk, further accelerating query performance.
Pillar 2: Vectorized Execution - A Superhighway for the CPU
After minimizing the data read from disk, the next challenge is to process it as efficiently as possible. Traditional databases often use a "row-at-a-time" processing model, where the engine loops through each row individually. This method incurs substantial overhead for every single row processed, as the CPU must repeatedly execute a long chain of instructions and function calls.
WorqDB employs vectorized query execution, a fundamentally different model. Instead of processing data row by row, it operates on data in large batches, or "vectors," which typically consist of 1,024 rows or more. This batch-oriented approach dramatically reduces the interpretive overhead per row and allows the CPU to operate far more efficiently.
The true power of this model is its ability to leverage Single Instruction, Multiple Data (SIMD) capabilities built into all modern CPUs. SIMD instructions allow a single operation—such as addition, comparison, or a logical AND—to be performed on an entire vector of data simultaneously in a single clock cycle. By organizing data into vectors that fit neatly into CPU registers, WorqDB can achieve a massive increase in computational throughput, making operations like filtering and aggregation orders of magnitude faster than traditional methods.
Pillar 3: Massively Parallel Processing (MPP) - Scaling Out, Not Just Up
To handle truly massive datasets and high user concurrency, WorqDB utilizes a "shared-nothing" Massively Parallel Processing (MPP) architecture. In this design, data is partitioned, or sharded, across a cluster of independent nodes. Each node has its own dedicated CPU, memory, and local storage and is responsible for a subset of the total data.
When a user submits a query, a coordinator node breaks it down into smaller pieces that are distributed to all the worker nodes in the cluster. Each node then executes its portion of the query in parallel on its local data. The intermediate results are gathered, merged, and returned to the user as a single, unified answer.
This architecture provides two key advantages:
Near-Linear Horizontal Scalability: Unlike traditional databases that often require "vertical scaling"—replacing a server with a single, larger, and much more expensive one—WorqDB scales "horizontally." To increase processing power or storage capacity, one simply adds more inexpensive, commodity servers to the cluster. This approach is far more cost-effective and allows performance to scale almost linearly with the number of nodes.
High Concurrency and Fault Tolerance: The distributed nature of the MPP architecture is inherently designed to handle many concurrent queries, as requests can be balanced across the cluster. Data is also typically replicated across multiple nodes, ensuring that the failure of a single machine does not lead to data loss or system downtime.
All customers get 1GB of data storage free for one year. To get started with WorqDB, log in or create a free account on worqhat.app.
Quick to get started and powerful to scale
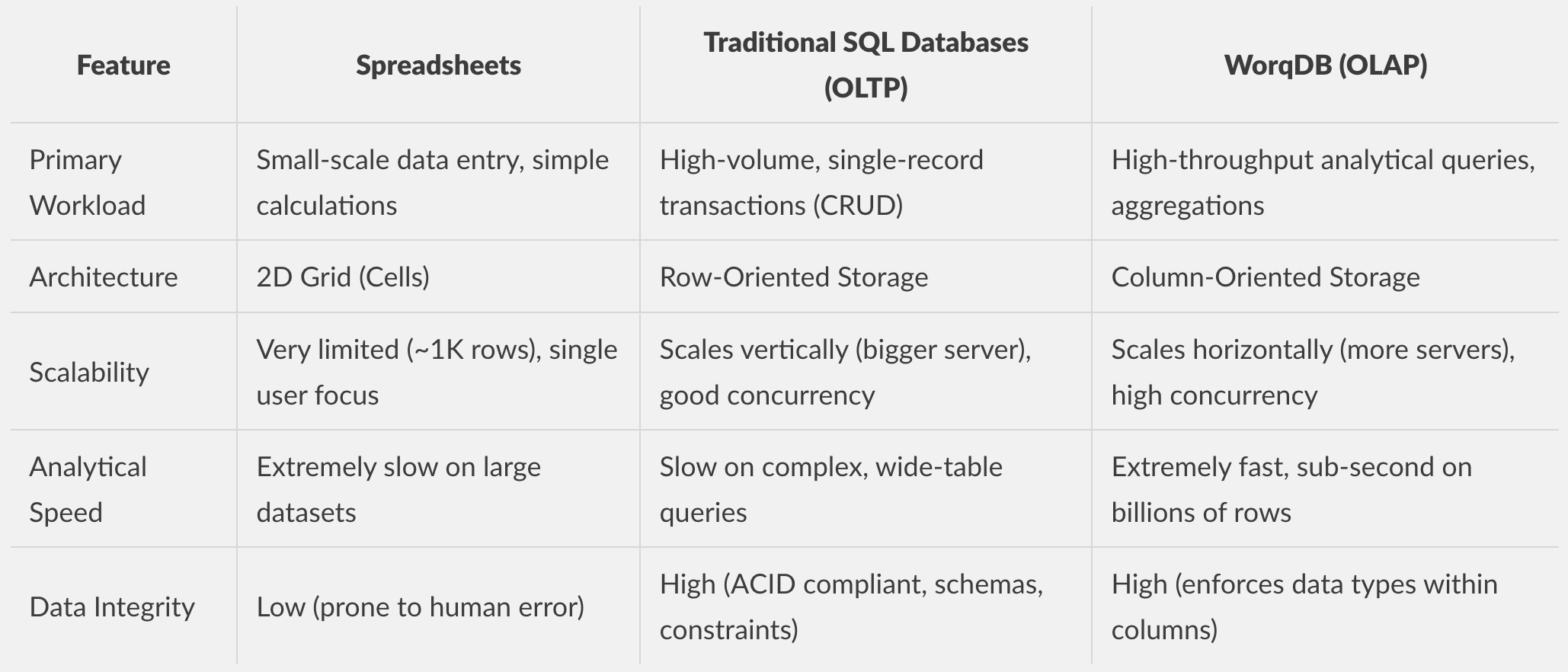
When you have an idea for a feature or app that needs to store data, you might initially choose the quickest solution—spreadsheets. Spreadsheets have traditionally been faster than setting up a new database, configuring existing infrastructure, or navigating through DevOps. However, spreadsheets aren't designed to store structured data at scale. They lack data integrity, foreign key relationships, and robust querying capabilities. Eventually, you'll need to migrate to a database when you require data safety enforcement or programmatic access to your data.
With WorqDB, you don't have to make these tradeoffs anymore. Get the power of a scalable SQL database with the speed and convenience of a spreadsheet.
How it works
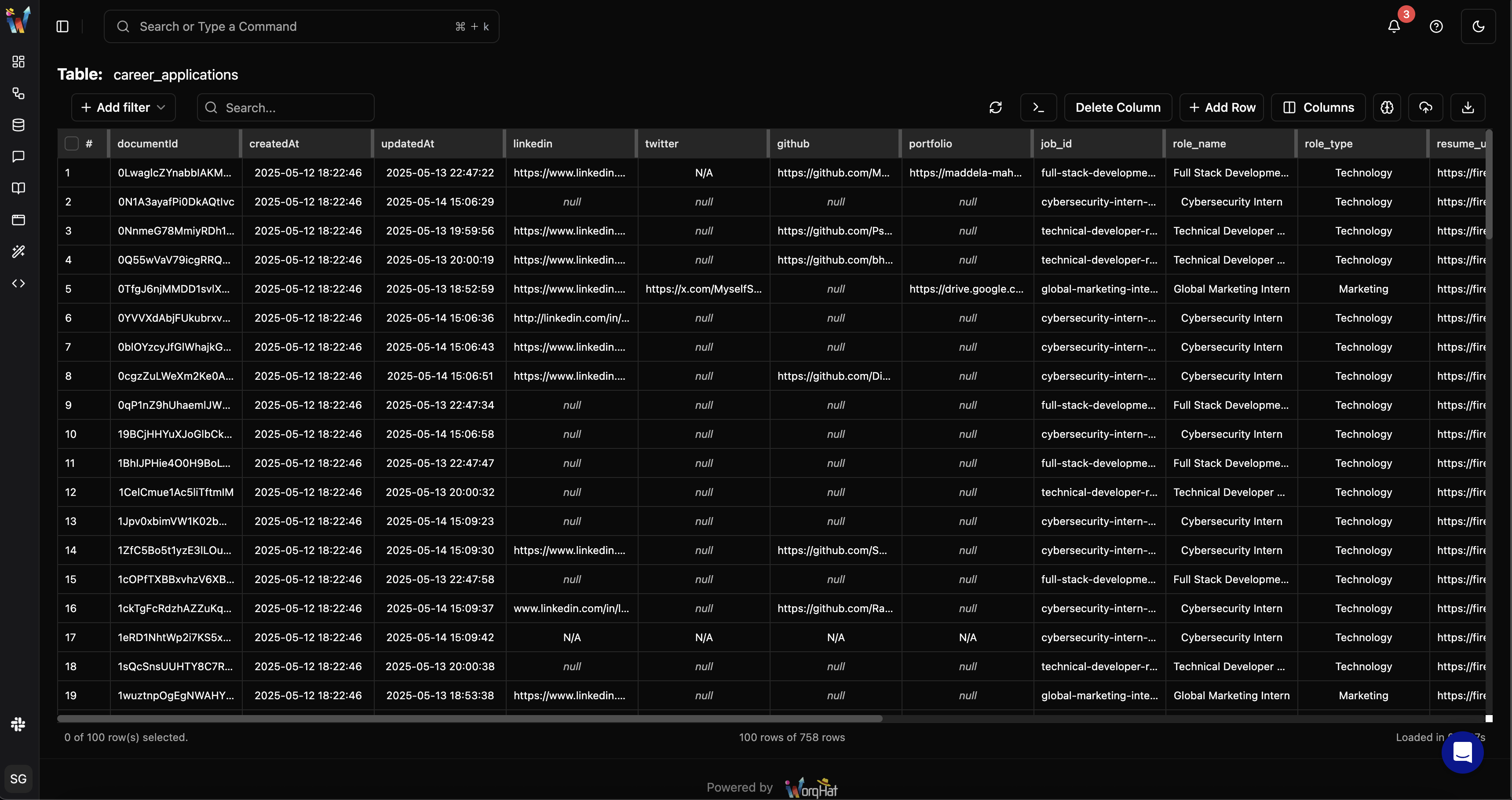
Every organization automatically gets a Completely Managed & Configurable OLAP database with their WorqHat account—no setup required.
- Quickly build out your schema with the WorqDB UI, where you can add tables and configure fields in a few clicks. You can also import your existing data from External Databases, Google Sheets, or other sources by uploading CSVs into your database.
- Filter, view, and edit your data while iterating on your app. You work with database tables with the same ease of a spreadsheet: rearrange columns, edit records directly, and scan and manage your data through filtering, sorting, and searching. All in the same place you are building your application.
Configure your database using natural language—simply describe what you want to set up, and WorqDB will help you implement it. This makes database management accessible even to those without extensive SQL knowledge.
Write SQL when you need to. You can directly query your WorqDB using standard SQL. Connect queries to components in WorqHat apps. Add reusable queries to your Query Library for other builders to reference and use.
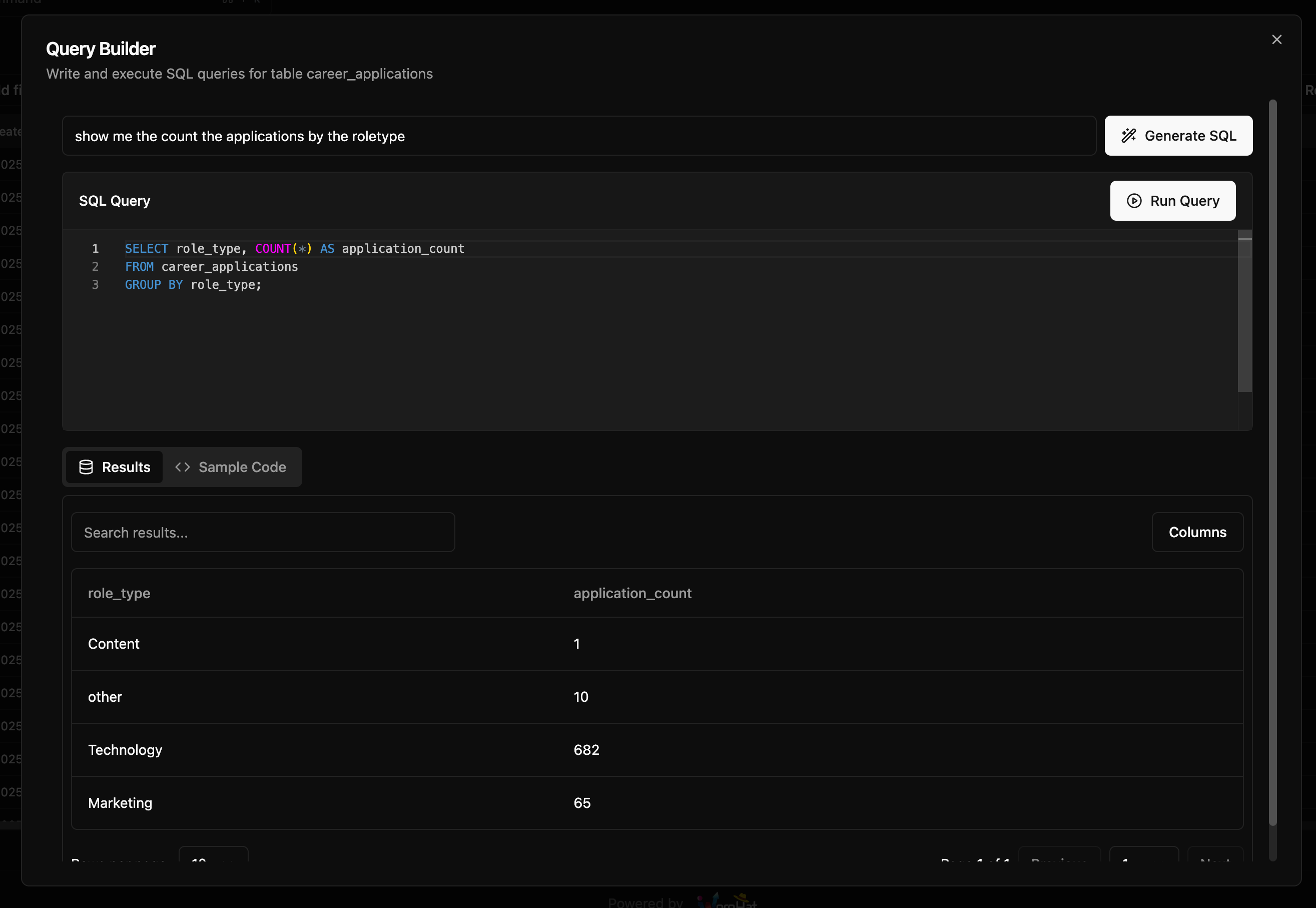
Connect to your database externally
With WorqDB, you get a fully-managed database. You're not locked into using it exclusively with WorqHat apps. Get connection strings so you can access the data you store in WorqDB anywhere, and integrate the data store with your broader data ecosystem and even export it to other tools.
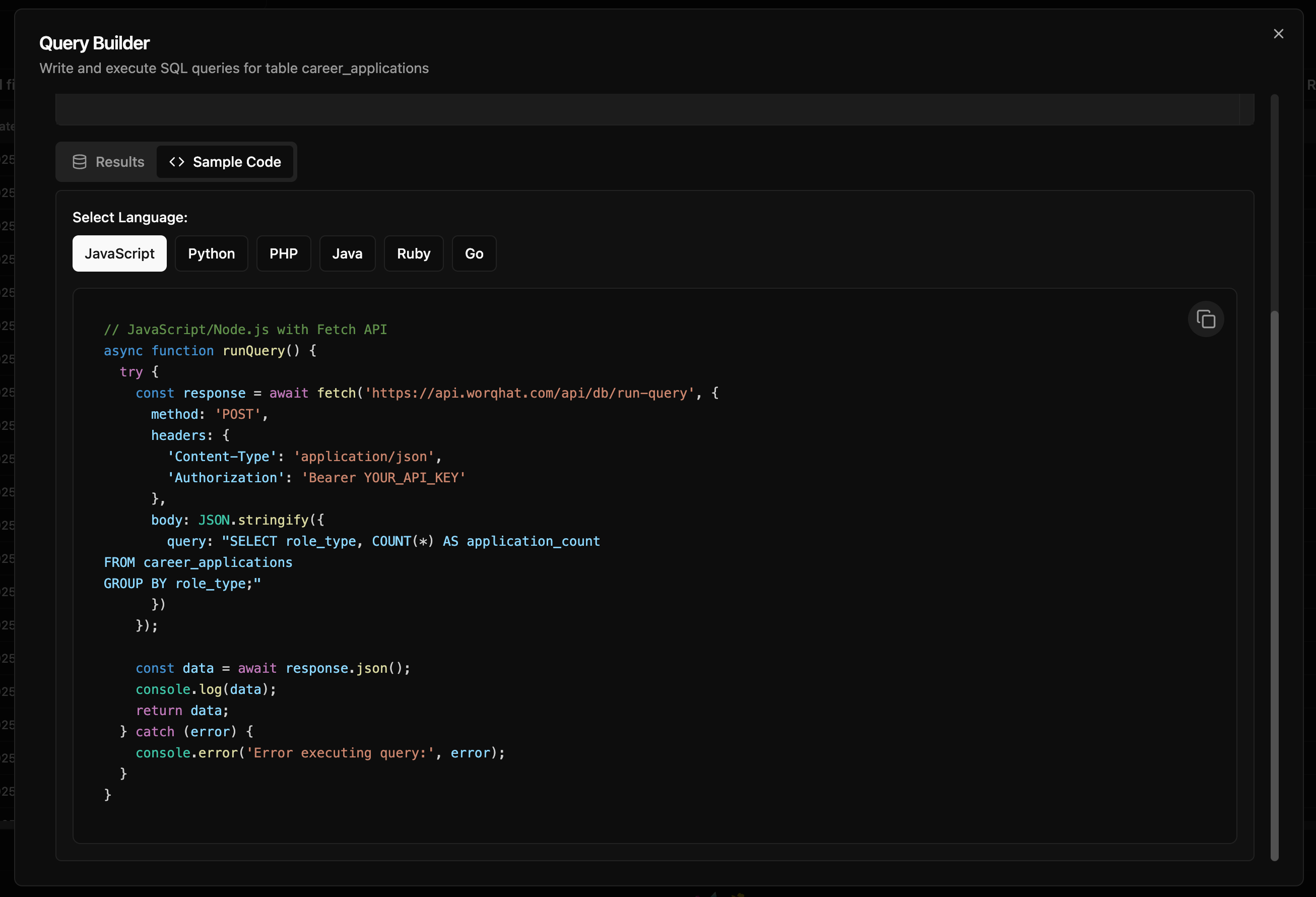
Users can connect to their database easily using simple protected API calls, ensuring secure access while maintaining flexibility for integration with other tools and services.
Get started
Customers can find WorqDB in your Resources tab on the WorqHat platform. All customers get 1GB of data storage free for one year—with no limits on rows or columns. Enterprise customers can contact us for custom storage options tailored to their specific needs.
If you're not a customer yet, sign up to create a free account on worqhat.app and check out our documentation to learn more about getting started with WorqDB.
Coming soon
We're working on exciting features that will allow you to run detailed queries, ask questions in natural language, and generate exportable charts while working with your data. These analytics capabilities will make it even easier to derive insights from your database without complex query writing.
Additionally, we're developing functionality to enable WorqDB to act as a data source for running language queries when connecting to workflows. This will create powerful integrations between your database and WorqHat's workflow automation tools, opening up new possibilities for AI-driven data processing.



Starting with WorqHat
is Simple, Fast and Free
Join thousands of developers, designers, and creators who use WorqHat to build amazing products. Get early access to new features, tutorials, and updates delivered straight to your inbox.
